








背景描述

GPU在工作负载中的主要作用是利用其出色的并行计算能力。在安全容器服务中,将GPU卡用于运行计算密集型工作负载对于某些特定的业务场景非常有价值,包括高性能计算、数据处理和分析加速、图形渲染和可视化优化等。通过将GPU与容器技术结合,可以实现灵活、高效且可扩展的计算环境,提供更好的用户体验和性能表现。本章节将详细介绍如何在部署工作负载时使用GPU卡能力。
前提条件
- 上传对应的GPU解决方案对接包:通过上传解决方案对接包,系统能够正确识别和使用GPU资源,以便在相应的工作负载中进行分配和调度。请确保在需要使用GPU资源时,已上传并配置了对应的GPU解决方案对接包。
- 容器运行时:当容器运行时为”安全运行时(rune)”时,支持使用GPU资源。
(注意:”守护进程集(DaemonSet)”和”定时任务(CronJob)”类型的工作负载不支持使用GPU。) - 资源预留:当需要勾选”使用GPU”时,建议设置CPU的参数值大于等于1,内存的参数值大于等于1024MiB。这样可以确保在使用GPU时,为工作负载分配足够的计算资源和内存资源,以获得良好的性能和稳定性。
操作步骤
目前平台中支持在安全容器中使用英伟达GPU设备和百度昆仑XPU设备。具体支持型号参见使用限制。下文将分别列出不同品牌GPU的操作步骤和示例,以帮助用户正确配置和使用GPU资源。
英伟达(NVIDIA)GPU设备
在支持使用GPU能力的工作负载类型创建界面中,勾选”使用GPU”选项,并选择”nvidia.com/gpu”作为GPU资源的类型。这样配置后,系统将为工作负载分配相应的GPU资源,以提供所需的计算能力和性能。创建容器组配置时,配置好容器(Pod) GPU参数,所有增量容器(Pod)默认共享GPU卡资源。
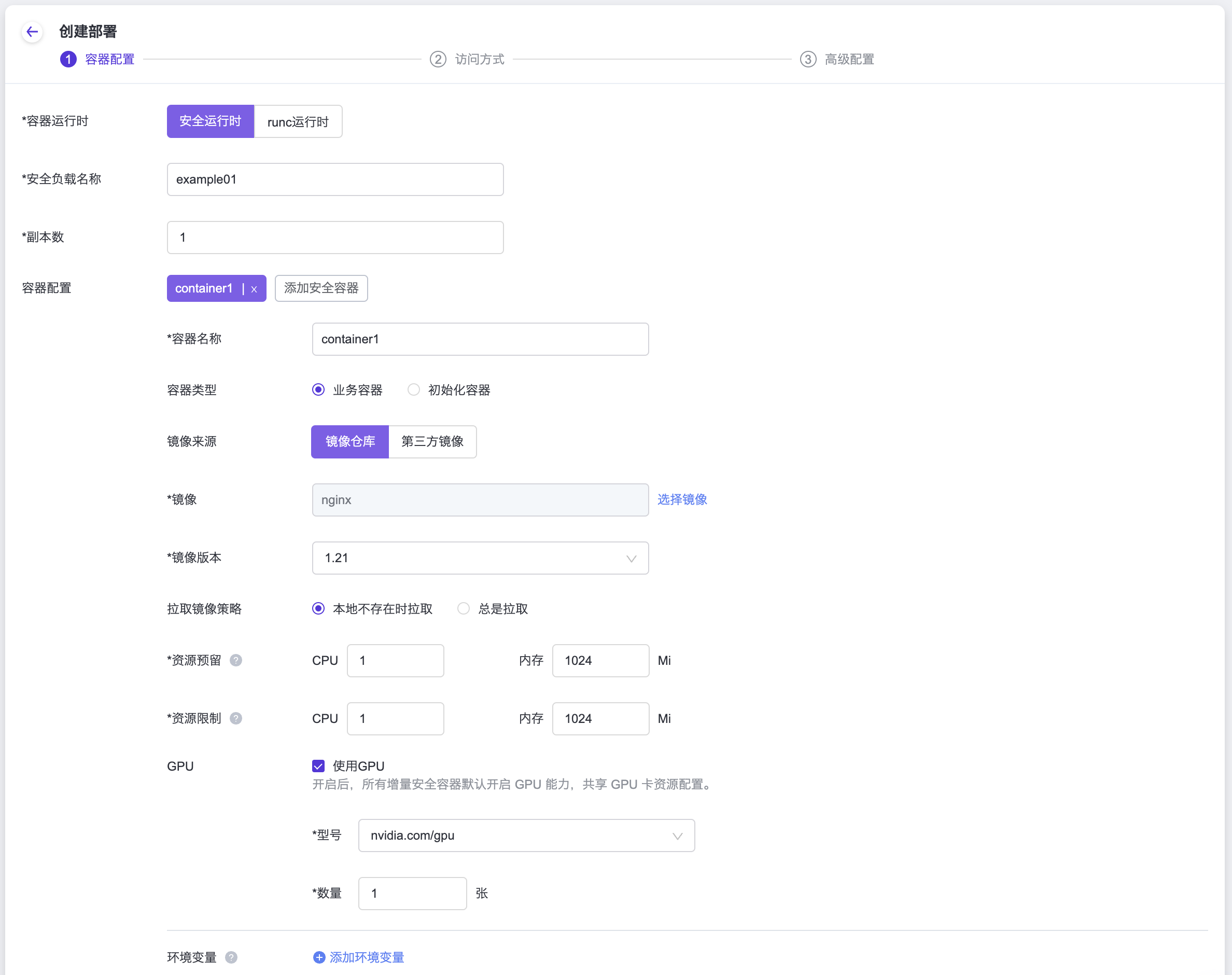
如果需要对容器(Pod)进行资源限制(limit)的设置,您可以在Pod的request字段中设置limit值。为了实现这个需求,您需要为Pod添加以下的annotation配置:
io.katacontainers.config.runtime.sandbox_cgroup_only: "false"Yaml示例:
template:
metadata:
labels:
my-app: perf-server0
annotations:
# 在limit中配置了memory时,需要添加如下注解
io.katacontainers.config.runtime.sandbox_cgroup_only: "false"
spec:
runtimeClassName: rune
containers:
- name: perf-server0
image: docker.io/test/perf:0.0.1
command:
- iperf3
args:
- -s
resources:
limits:
cpu: "2"
memory: 2Gi
# 配置GPU资源数量
nvidia.com/gpu: "1"
requests:
cpu: "2"
memory: 2Gi
nvidia.com/gpu: "1"百度昆仑XPU
在支持使用GPU能力的工作负载类型创建界面中,勾选”使用GPU”选项,并选择”baidu.com/XPU”作为GPU资源的类型。这样配置后,系统将为工作负载分配相应的GPU资源,以提供所需的计算能力和性能。创建容器组配置时,配置好容器(Pod) GPU参数后,所有增量容器(Pod)默认共享GPU卡资源。
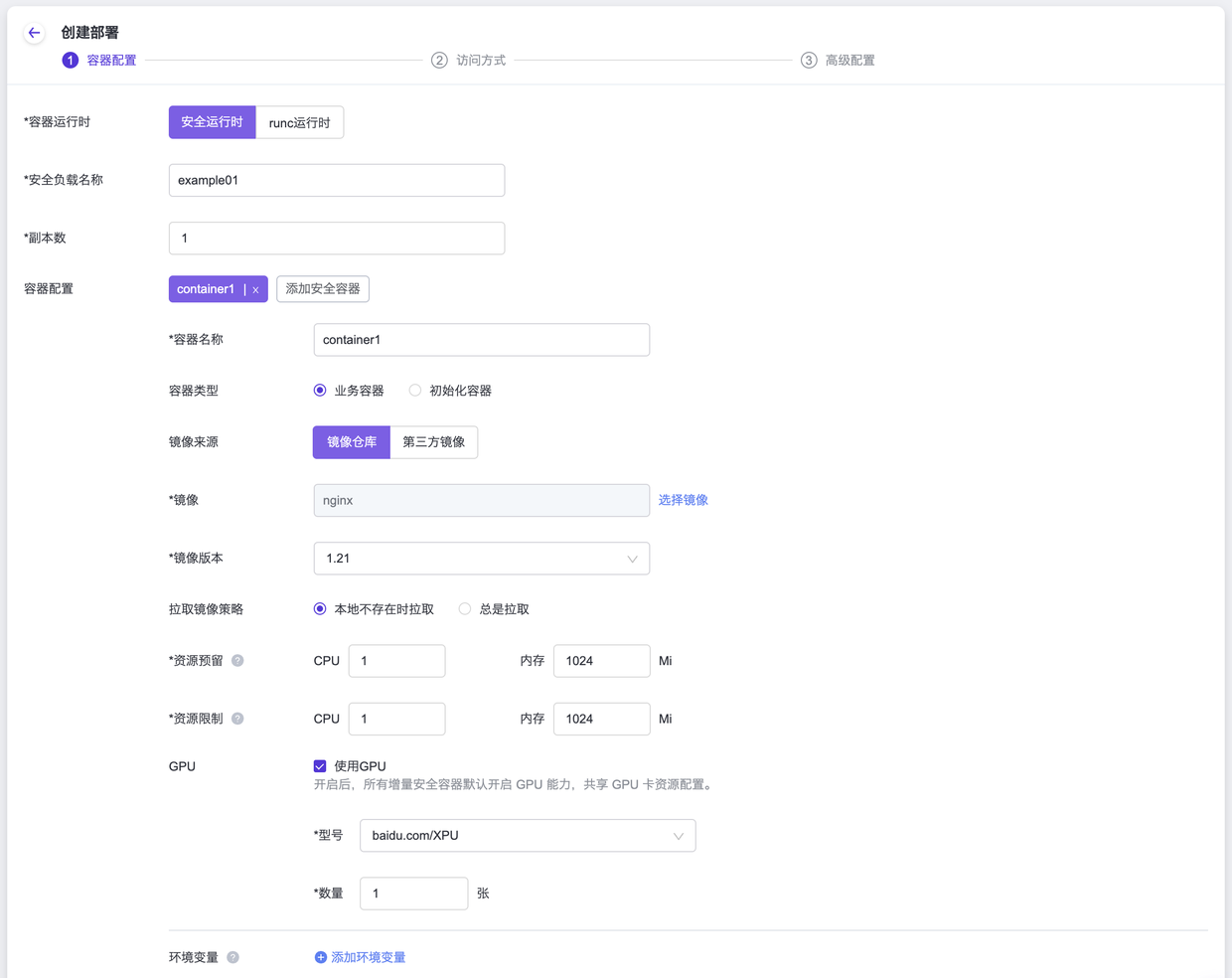
如果需要对容器(Pod)进行资源限制(limit)的设置,您可以在容器(Pod)的“request”字段中设置“limit”值。为了实现这个需求,您需要为容器(Pod)添加以下的“annotation”配置:
io.katacontainers.config.runtime.sandbox_cgroup_only: "false"Yaml示例:
template:
metadata:
labels:
my-app: perf-server0
annotations:
# 在limit中配置了memory时,需要添加如下注解
io.katacontainers.config.runtime.sandbox_cgroup_only: "false"
spec:
runtimeClassName: rune
containers:
- name: perf-server0
image: docker.io/test/perf:0.0.1
command:
- iperf3
args:
- -s
resources:
limits:
cpu: "2"
memory: 2Gi
# 配置XPU资源数量
baidu.com/XPU: "1"
requests:
cpu: "2"
memory: 2Gi
baidu.com/XPU: "1"此外,百度昆仑XPU支持指定某个容器对象独享某个具体的GPU卡(其他容器不可见),可通过环境变量: CXPU_VISIBLE_DEVICES: 1 设置GPU卡隔离。当环境可用GPU卡未被指定完,配置后且未被隔离的GPU卡为所有容器共享资源。当环境可用GPU卡被指定完,剩余的容器无可用的GPU卡资源。
百度昆仑XPU在各个容器(Pod)中的可见性环境变量:CXPU_VISIBLE_DEVICES可以设置值为all或者是卡序号(1, 2, 3)
Yaml示例:
template:
metadata:
labels:
my-app: perf-server0
annotations:
# 在limit中配置了memory时,需要添加如下注解
io.katacontainers.config.runtime.sandbox_cgroup_only: "false"
spec:
runtimeClassName: rune
containers:
- name: perf-server0
image: docker.io/test/perf:0.0.1
command:
- iperf3
args:
- -s
env:
- name: CXPU_VISIBLE_DEVICES
value: ALL
resources:
limits:
cpu: "2"
memory: 2Gi
# 配置GPU资源数量
nvidia.com/gpu: "1"
requests:
cpu: "2"
memory: 2Gi
nvidia.com/gpu: "1"附录
为了正确使用GPU资源,请确保准确指定GPU卡的型号对应的资源名称:
| GPU卡型号 | 资源名称 |
|---|---|
| 英伟达(NVIDIA)GPU设备 | nvidia.com/gpu |
| 百度昆仑XPU设备 | baidu.com/XPU |


